I keep improving Kiri to measure the efficiency of MAIA. Today I bring you a new short post with its latest enhancements and improvements. While in the previous post I focused on its autonomy, in this I will focus on its speed.
I am of the opinion that each project must have its identity. Therefore, before telling you about its improvements, I present you its logo:
![]()
It is not very good, but at least it is quite descriptive (IRI in a box) 🙂
When we talk about improving the speed of an application we can think of several things such as remove a bottleneck, parallelize the execution, reduce order of complexity or use a new library among others things. I am sorry to disappoint those who expect an ingenious solution … .
To put you in context, Kiri is an application that allows you to running a private IOTA testnet in a Low Cost Single Board Computer (LCSBC), something that can be very useful to carry out certain types of tests.
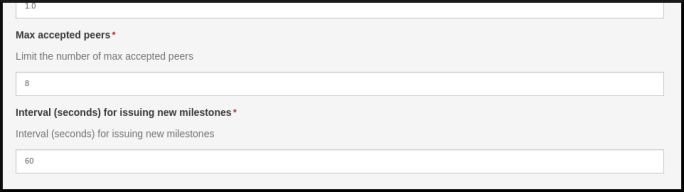
What is not necessary to running a private IOTA testnet in a LCSBC? Neither run the IXI hub nor load the addresses of previous epochs.

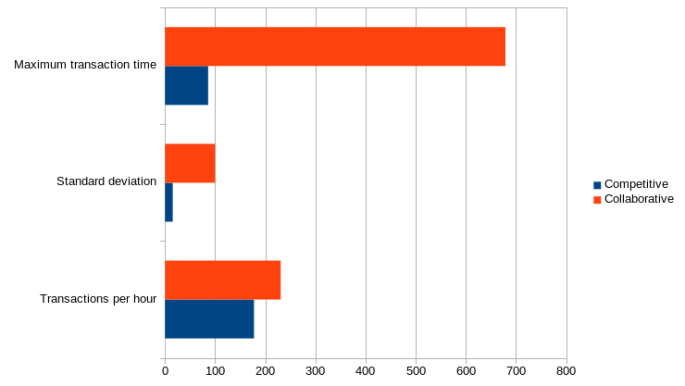
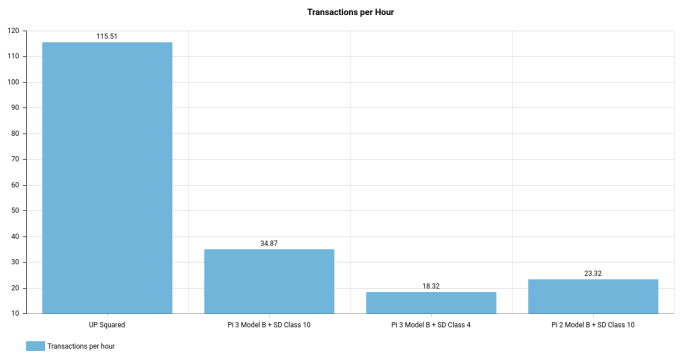
To what extent does the above affect the speed of Kiri? Well, I think an image here is worth more than a thousand words.


I must admit that the graphs do not indicate anything about the overall speed, but the reason is simple, it is complicated to measure accurately and it is logical to conclude that (usually), if you use less computational resources the overall speed will be higher. I think it is unnecessary to develop a convoluted metric to prove it, it is only necessary to use the new version of Kiri to realize that it works faster than the previous one (at least 25%).
Any other improvement? Some other more, although most of them are focused on fixing errors and improving the integration of IRI in Kura.
That’s all. In a few days I will bring you news from MAIA.
In case you want to donate some IOTAs to support my work, send them to my personal IOTA address:
KIFEHFFMQDPHLHGURUXDZGTJVDZMDLCFSVXXRNXKCIXJZSJNBWULBLQXYSNZNVGIJXVCITXREHUUKCHGDCSEBGYDEB (it is no longer my address, use my MAIA)
Or better yet, send them to my MAIA (we are making changes to the protocol and sometimes the node that we use is down, so for now it is better that we do not take risks :’) ): donation address.